
Das Sammeln von Code Coverage-Daten verlangsamt die Testausführung. In einem früheren Artikel haben Sebastian Heuer und ich erklärt, wie diese Verlangsamung bei der Verwendung von Xdebug reduziert werden kann.
Seit wir diesen Artikel geschrieben haben, hat Joe Watkins PCOV veröffentlicht , eine neue PHP-Erweiterung für das Sammeln von Code Coverage-Daten. PCOV kann im Gegensatz zu Xdebug nur Line Coverage-Daten sammeln, dies aber wesentlich schneller als Xdebug 2. Xdebug kann über Line Coverage hinaus auch Branch Coverage und Path Coverage ermitteln. PHPUnit unterstützt PCOV seit Version 8, die im Februar 2019 veröffentlicht wurde.
Kürzlich implementierte Doug Wright die Unterstützung für Branch Coverage und Path Coverage in php-code-coverage
. Das ist die Bibliothek, die von PHPUnit für das Sammeln, Verarbeiten und Berichten von Code Coverage verwendet wird. Wo er schon einmal dabei war, führte er auch einige überfällige Aufräumarbeiten durch, welche die CLI-Optionen --dump-xdebug-filter
und --prepend
von PHPUnit, die wir in unserem früheren Artikel besprochen haben, überflüssig machen. Sie sind nun als „deprecated“ markiert und werden nächstes Jahr mit PHPUnit 10 verschwinden.
Bessere Informationen dank PHP-Parser
PHPUnit 9.3 wurde am 7. August 2020 veröffentlicht und verwendet php-code-coverage 9.0 für die Code Coverage-Funktionalität. Diese neuen Versionen machten Branch Coverage und Path Coverage zum ersten Mal mit PHPUnit nutzbar.
Zusätzlich zu den neuen Funktionen gab es unter der Haube von php-code-coverage eine Menge Änderungen. Wertobjekte wurden eingeführt, um alte Array-Strukturen zu ersetzen, die aufgrund mangelnder Typsicherheit schwer zu verstehen waren.
Die Änderung, die für diesen Artikel am relevantesten ist, war jedoch der Schritt, Nikita Popovs ausgezeichnete PHP-Parser Bibliothek als Grundlage für die statische Analyse zu verwenden. Wir verwenden jetzt einen abstrakten Syntaxbaum , um beispielsweise zu ermitteln, ob eine Codezeile ausführbar ist oder nicht. Das Ergebnis dieser Analyse ist jetzt genauer als zuvor und der Code für diese Analyse ist jetzt viel einfacher zu verstehen und zu warten.
Bei der Analyse von Code mit PHP-Parser wird das Besucher
Entwurfsmuster eingesetzt: NodeVisitor
-Objekte besuchen jeden Knoten des abstrakten Syntaxbaums einer Quelldatei. Hier ist eine Liste der NodeVisitor
-Objekte, die in php-code-coverage 9.0 verwendet werden:
-
CodeUnitFindingVisitor -
ExecutableLinesFindingVisitor -
IgnoredLinesFindingVisitor -
CyclomaticComplexityCalculatingVisitor -
LineCountingVisitor
Wir benutzen diese NodeVisitor
-Objekte, um herauszufinden, welche Code-Zeilen ausführbare Anweisungen enthalten, welche Code-Zeilen ignoriert werden sollen (beispielsweise basierend auf @covers
oder @codeCoverageIgnore
Annotationen), welche Code-Einheiten (Klassen, Traits, Funktionen) in einer Quelldatei deklariert sind, wie viele Code-Zeilen (Lines of Code, Comment Lines of Code, Non-Comment Lines of Code, Logical Lines of Code) eine Quelldatei hat, und was die zyklomatische Komplexität von Funktionen und Methoden in einer Quelldatei ist.
Oh nein. Es ist langsam!
Ich hatte erwartet, dass die Verwendung von PHP-Parser für die statische Analyse in php-code-coverage die Code Coverage-Analyse mit PHPUnit langsamer machen würde. Bei den Benchmarks, die ich vor der Veröffentlichung von PHPUnit 9.3 durchgeführt habe, konnte ich jedoch keine signifikante Verlangsamung feststellen. Deshalb war ich von der Leistungsregression überrascht, die fast unmittelbar nach der Veröffentlichung der neuen Version gemeldet wurde.
Die offensichtliche Lösung für den Umgang mit einer teuren Operation (in unserem Fall die statische Analyse), bei der sich das Ergebnis nur ändert, wenn sich die Eingabe (in unserem Fall die Quelldateien) ändert, ist Caching. Und so konzentrierte ich die Verwendung von PHP-Parser für Quelldateien, die von mindestens einem Test ausgeführt werden, in der neuen Klasse
ParsingCoveredFileAnalyser
. Dann extrahierte ich die
CoveredFileAnalyser
Schnittstelle aus dieser Klasse:
| interface CoveredFileAnalyser |
| { |
| public function classesIn ( string $filename ) : array ; |
| public function traitsIn ( string $filename ) : array ; |
| public function functionsIn ( string $filename ) : array ; |
| public function linesOfCodeFor ( string $filename ) : LinesOfCode ; |
| public function ignoredLinesFor ( string $filename ) : array ; |
| } |
Schließlich habe ich eine zusätzliche Implementierung geschaffen, die das Caching übernimmt, den
CachingCoveredFileAnalyser
:
| final class CachingCoveredFileAnalyser |
| extends Cache implements CoveredFileAnalyser |
| { |
| private $coveredFileAnalyser ; |
| public function __construct ( |
| string $directory , |
| CoveredFileAnalyser $coveredFileAnalyser |
| ) |
| { |
| parent :: __construct ( $directory ) ; |
| $this -> coveredFileAnalyser = $coveredFileAnalyser ; |
| } |
| public function classesIn ( string $filename ) : array |
| { |
| if ( $this -> cacheHas ( $filename , __METHOD__ ) ) { |
| return $this -> cacheRead ( $filename , __METHOD__ ) ; |
| } |
| $data = $this -> coveredFileAnalyser -> classesIn ( $filename ) ; |
| $this -> cacheWrite ( $filename , __METHOD__ , $data ) ; |
| return $data ; |
| } |
| // ... |
| } |
ParsingCoveredFileAnalyser
wird direkt verwendet, wenn der Cache für statische Analyseergebnisse deaktiviert ist. CachingCoveredFileAnalyser
wird verwendet, wenn der Cache für statische Analyseergebnisse aktiviert ist. Diese Klasse delegiert an ParsingCoveredFileAnalyser
, wenn die angefragten Daten nicht im Cache gefunden werden, und gibt andernfalls das gecachte Ergebnis zurück.
Dies schien „gut genug“ zu sein und php-code-coverage 9.1.0 wurde veröffentlicht . Erinnerst du dich, was ich am Anfang dieses Artikels geschrieben habe? Caching macht die Dinge schneller ... außer, wenn es nicht so ist.
Ein schlechter Cache ist schlimmer ...
Mitte September 2020 bekam ich eine E-Mail von Martin Völker, der als IT-Manager und Softwareentwickler bei Crew United arbeitet. Mittlerweile weiß ich, dass wer in der deutschsprachigen Filmbranche arbeitet, an diesem Netzwerk nicht vorbeikommt. Martin Völker wandte sich an mich mit einem Problem, aber das lasse ich ihn besser selbst berichten:
Organisation von Entwicklungsarbeit und Test-Automatisierung
Die Entwicklungsarbeit an unserer Plattform ist in Sprints organisiert. Ungefähr im Monatsrhythmus werden Detailverbesserungen und neue Features veröffentlicht.
Als Backend dient ein API-System auf PHP-Basis. Nebenläufige Ziele der Entwicklungsarbeit beinhalten die Verbesserung der Code-Qualität – gemessen an zahlreichen Kennzahlen wie zum Beispiel CheckStyle-Reports, dem PHP Mess Detector (PHPMD), statischer Code-Analyse und Code-Coverage-Reports. Ein Sprint beinhaltet das Ziel, dass diese Kennzahlen sich nicht verschlechtern – trotz wachsender Größe der Code-Basis. Im besten Fall sind die Zähler von Checkstyle und PHPMD am Ende niedriger.
Jeder Git-Commit im develop
Branch durchläuft eine Kette von Jobs auf dem verwendeten Jenkins-CI-System:
- PHPUnit führt alle Unit- und Feature-Tests (innerhalb von circa fünf Minuten) aus – derzeit rund 8.300 Tests; wenn es keinen Fehler gibt ...
- wird der Code-Stand auf zwei Test-Server aufgespielt – einen für manuelle Tests und die Abnahme von Sprint-Features, einen für automatisierte Tests und Behat-Frontend-Tests; dies dauert eine halbe Minute
- im Anschluss erzeugt ein weiterer Job die beschriebenen Kennzahlen und mit PHPUnit wird ein Code-Coverage-Report generiert – dies ist zeitaufwändig und dauert in der Summe rund 21 Minuten; wenn es keinen Fehler gibt ...
- werden die Behat-Tests für das Frontend ausgeführt – derzeit rund 250 Szenarien und knapp 4.000 Einzelschritte; dies dauert etwa 40 Minuten
Da alle Test-Schritte – also alle außer dem Deployment in Schritt 2 – gegen dasselbe Test-System laufen, müssen sie exklusiv laufen und andere Jenkins-Jobs so lange blockieren.
Wenn nun also die Durchlaufzeit von einem Schritt beziehungsweise Job deutlich steigt, beeinflusst das die anderen negativ. Es dauert beispielsweise länger, bis auf dem Test-System neu implementierte Features bereitstehen.
Am Rande sei noch erwähnt, dass es zwei, drei weitere Jobs auf dem Jenkins-System gibt, die ebenfalls exklusiv laufen müssen – etwa automatisierte Tests mit PHPUnit auf dem master
Branch.
Ein weiteres nebenläufiges Ziel ist deshalb die Beschleunigung der Tests, die mit PHPUnit ausgeführt werden. Und somit auch die schnellere Erzeugung des Code-Coverage-Reports. Bevor Änderungen in das Repository gepusht werden dürfen, müssen die Tests ausgeführt werden und fehlerfrei durchlaufen. Die Entwickler bekommen Veränderungen der Laufzeit hier direkt zu spüren.
Wie sich die Laufzeitprobleme bemerkbar machten
Für den September 2020 stand die Aktualisierung von PHPUnit 9.2 (mit php-code-coverage 8.0) auf PHPUnit 9.3 (mit php-code-coverage 9.1) an. Da dies Änderungen an PHPUnit-XML-Konfigurationsdateien für Code-Coverage erfordert, war etwas Zeit im Sprint dafür reserviert. Dankenswerterweise ist das neue Format viel deutlicher , die vier oder fünf Dateien im Projekt waren schnell geändert.
Nach einem ersten Durchlauf auf dem Jenkins-System gab es die erste Überraschung. Mit den neuen Versionen ist die benötigte Zeit um rund 90 % angestiegen. Auf dem lokalen Entwicklungsrechner konnte dies reproduziert werden.
Erste Schritte der Ursachenforschung
Die Tests auf dem Entwicklungsrechner laufen auf Windows. Es wäre nicht der erste Fall, bei dem hier die Ursache zu finden ist. Aber auch mit einem lokalen Linux-System hatte sich dasselbe Bild ergeben. Das Jenkins-System läuft auch auf Linux. Überall ein sehr ähnliches Verhalten. Das schied also aus.
„Ich kann ja nicht der erste und einzige sein, der dieses Problem hat“ – ein üblicher Gedanke. Zudem ist das neue PHPUnit schon bei der zehnten Unterversion – 9.3.10. Eine Kinderkrankheit wird es wohl auch nicht sein.
Also prüft man Bug-Reports bei GitHub zu PHPUnit und php-code-coverage. Und siehe da, das Ticket 789 beschreibt genau das Problem. Also einfach alles tun, was dort zur Lösung beschrieben ist ... und Problem gelöst!
Es klingt ganz einfach und logisch: Die verwendete Bibliothek zur statischen Code-Analyse wurde getauscht, da die alte schwer zu warten war. Die neue – PHP-Parser – ist sauber aufgebaut, konzeptbedingt aber langsamer. Das wird in Bezug auf die deutlich überwiegenden Vorteile aber in Kauf genommen.
Um den Effekt – langsamer als zuvor – zu mildern, gibt es den neuen Cache für die Ergebnisse der aufwendigen statischen Analyse. Man muss nur in der Konfigurationsdatei den Ordner für den Cache setzen. Mit dem ersten Durchlauf wird der befüllt und ab dann läuft es so schnell, dass nur noch ein geringer Unterschied zur Vorgänger-Version auftritt.
Also den Cache aktiviert und – wie ebenfalls beschrieben – PHPUnit mit dem neuen Parameter --warm-coverage-cache
aufgerufen. Nach rund einer Minute war das erledigt auf dem Entwicklungsrechner.
Dann jedoch gab es die nächste Überraschung. Auch beim zweiten und dritten Durchlauf, um einen Code-Coverage-Report zu erzeugen, war die Laufzeit nicht niedriger – sie war mit aktiviertem Cache rund 3x so hoch wie ohne.
Ursachenforschung zum Cache-Problem
Kann man etwas ganz falsch machen, wenn man nur einen Ordnerpfad für die Cache-Dateien in der Konfigurationsdatei setzt? Liefen vielleicht parallel andere Prozesse? Auch ein vierter und fünfter Versuch hatte – bis auf wenige Sekunden Abweichung – dasselbe Ergebnis geliefert. Fast eine Stunde benötigte PHPUnit, um die Daten für den Report zu generieren. Vielleicht ist das jetzt ein Nur-auf-Windows-Problem – könnte ja sein. Aber auf dem Jenkins-Server dasselbe Ergebnis. Der Laufzeit-Trend in Abbildung 1 zeigt es deutlich.
Abbildung 1: Laufzeiten der Jenkins-Builds bei Crew United
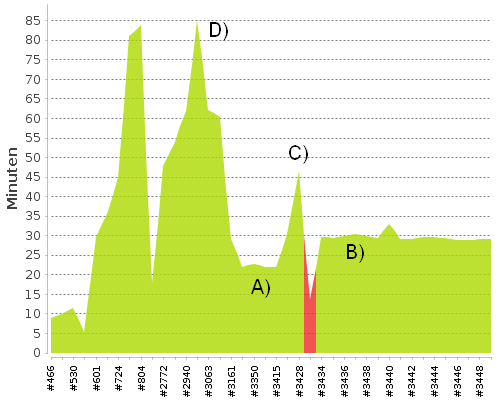
A. PHPUnit 9.2 mit php-code-coverage 8.0
B. PHPUnit 9.3 mit php-code-coverage 9.1 ohne Cache
C. PHPUnit 9.3 mit php-code-coverage 9.1 mit Cache
D. PHPUnit 9.2 mit php-code-coverage 8.0 und Xdebug anstatt PCOV
Die nächste Überraschung war im Cache-Ordner selbst zu finden. Fast 38.000 Dateien lagen darin. Es handelt sich um serialisierte PHP-Daten. Nach kurzer Analyse war zu sehen, dass auch der Namespace der Klassen enthalten ist. Eine erste Vermutung war, dass vielleicht jeweils eine Cache-Datei für alle Klassen bzw. Dateien aus dem vendor
-Verzeichnis erzeugt wurde. Dies wäre ein denkbarer Fehler. Code-Coverage-Reports werden nur für die Namespaces von Crew United erzeugt; Klassen im vendor
-Ordner sind nicht relevant. Diese Vermutung konnte aber schnell widerlegt werden. In den Dateien im Cache waren keine fremden Klassen zu finden.
Kontaktaufnahme mit Sebastian Bergmann
An diesem Punkt war mir klar, dass ich nicht weiter komme und die Ursache „irgendwo“ in PHPUnit oder php-code-coverage zu finden sein muss. Ein Problem, dass niemandem zuvor aufgefallen ist. Vielleicht liegt es auch schlicht an der Größe des Projekts mit einigen tausend Dateien. Hier könnten Effekte deutlicher werden, als in kleineren. Aber ein Cache sollte immer beschleunigen.
Mein Gedanke war, jetzt schreibe ich ihm einfach mal eine E-Mail. Ich kenne ihn von einigen großen PHP-Konferenzen und der ein oder anderen PHP-Usergroup in München. Er als Sprecher, ich als Zuhörer. Mit sehr hoher Wahrscheinlichkeit kennt er mich nicht, schon gar nicht namentlich. Wird da eine Antwort kommen und wenn ja, wann?
In der E-Mail waren die drei großen Probleme beschrieben:
- Die rund 90 % höhere Laufzeit im Vergleich zur Vorversion
- Die Verdreifachung der Laufzeit mit aktiviertem Cache
- Die erstaunlich große Zahl an Dateien im Cache
Zudem konkrete Zahlen aus den PHPUnit-Durchläufen – wie auch oben zu sehen.
Zwei Tage später hatte ich tatsächlich eine Antwort im Posteingang. Zu meinen Fragen ungefähr folgende Rückmeldungen:
- Der neue PHP-Parser ist langsamer, ja. In diesem Ausmaß aber bisher nicht bekannt.
- Mit Cache läuft es schneller. Auch dieses Verhalten ist nicht bekannt.
- Pro PHP-Datei im Projekt landen sechs Dateien im Cache-Ordner.
Zudem das Angebot, eine Videokonferenz mit Screen-Sharing zu machen – gedeckelt auf eine Stunde. Dann soll ich zeigen, wie sich die Probleme bei mir auswirken.
Dieses unerwartete Angebot nahm ich gerne an. Wir vereinbarten einen Termin und ich sicherte zu, bis zum Termin schon mal Material vorzubereiten. Konkret hatte ich zu bieten:
- Aufrufe von PHPUnit mit und ohne Cache – am Zeichnen der Pünktchen war der Geschwindigkeitsunterschied schon deutlich zu sehen
- Profiling-Daten (erzeugt mit Xdebug) mit und ohne Cache für die ersten 100 der 8.300 Tests
Ablauf der Videokonferenz
Nach kurzer Beschreibung zum Projekt gingen wir die PHPUnit-Konfigurationsdatei durch – keine Auffälligkeiten. Auch hier der Ausschluss, dass es sich um ein Windows-only-Problem handelt.
Erstes Erstaunen trat auf, als wir uns die Profiling-Daten vom Durchlauf mit aktiviertem Cache ansahen (siehe Abbildung 2).
Abbildung 2: Auswertung der Profiling-Daten in PhpStorm
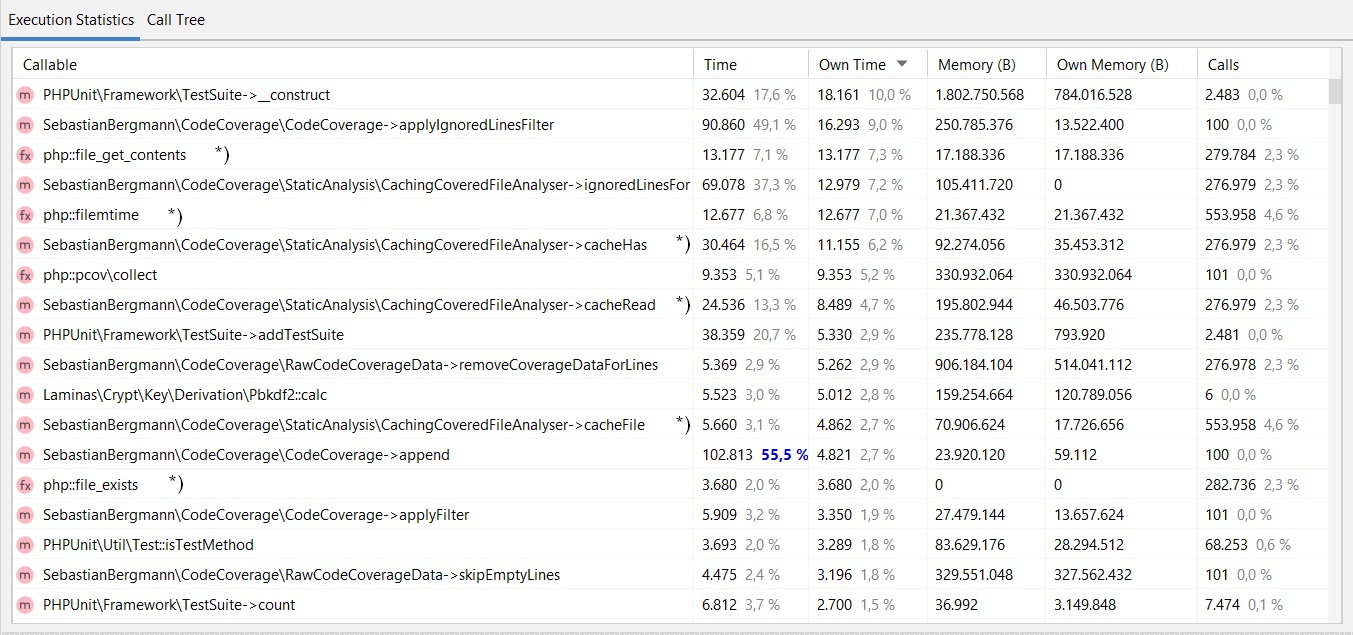
Mit PhpStorm kann man mit Xdebug erzeugte Profiler-Dateien öffnen, die Tabelle ist die Ansicht davon. In der Spalte „Callable“ sind die Namen der aufgerufenen Funktionen zu sehen, in „Own Time“ ist der Laufzeitanteil der Funktion in Prozent der Gesamtzeitlaufzeit zu sehen. Auffällige Funktionsaufrufe sind mit *) markiert. Weshalb steht „php:filemtime“ mit 7 % so weit oben? Weshalb steht „CachingCoveredFileAnalyse->cacheHas“ mit 6,2 % so weit oben?
Der Verdacht fiel schnell auf ein Problem mit dem Cache selbst. Da PHPUnit und php-code-coverage über Composer im Projekt eingebunden sind, konnten wir direkt Änderungen vornehmen und die Auswirkungen überprüfen. Allerdings zeigte sich auch schnell, dass die Lösung hier nicht mal schnell mit zwei, drei geänderten Zeilen zu erreichen ist.
Zu diesem Zeitpunkt konnte Sebastian Bergmann das Problem bei sich auch noch nicht reproduzieren. Wir beendeten die Videokonferenz mit folgendem Plan:
- Sebastian Bergmann prüft die über das Profiling ermittelten auffällig langsamen Methoden und baut den Cache um.
- Wenn die Änderungen bereitstehen, hole ich sie mir in das Projekt, führe PHPUnit aus und gebe Rückmeldung.
Die weiteren Stunden – der Erfolg
Nach dem genannten Plan gab es einige Durchläufe nach folgendem Muster:
- Sebastian Bergmann: „Ich habe ... geändert.“
- Martin Völker: „Damit konnte ich leider noch keine Verbesserung feststellen.“
Am nächsten Tag – sehr früh gegen 06:15 Uhr – kam die Rückmeldung:
- Ich habe nochmal ein paar I/O-Operationen eliminiert
- Ich kann das Problem mittlerweile reproduzieren
Also nochmal den jüngsten Code-Stand von PHPUnit und php-code-coverage in das Projekt holen und ... es war tatsächlich geschafft. Auch meine Durchlaufzeiten mit Cache waren besser.
Meine Antwort an Sebastian Bergmann: „Die jüngsten Optimierungen wirken, beschleunigen den Durchlauf bei mir und lösen die Cache-Problematik. Vielen Dank!“
An dieser Stelle möchte ich mich bei Martin Völker für die nette Videokonferenz sowie die gute Zusammenarbeit bei der Lösung dieses Problems bedanken.
Woran lag's denn nun?
Die Ursache für den von Martin Völker berichteten signifikanten Leistungsrückgang war zweiteilig. Das Ergebnis der von ParsingCoveredFileAnalyser
durchgeführten statischen Analyse wurde von CachingCoveredFileAnalyser
in fünf Cache-Dateien pro Quelldatei gespeichert. Daher waren fünf I/O-Operationen erforderlich, um das Ergebnis der von ParsingCoveredFileAnalyser
durchgeführten Arbeit im Cache zu lesen. Aber es kommt noch schlimmer. Die Methoden classesIn()
, traitsIn()
, functionsIn()
und linesOfCodeFor()
werden nur einmal pro Quelldatei aufgerufen. Die Methode ignoredLinesFor()
wird jedoch nach jedem Test einmal pro ausgeführter Quelldatei aufgerufen. Die ursprüngliche Implementierung des Cache liest die Informationen für ignoredLinesFor()
immer wieder aus dem Cache. Im Nachhinein ist es offensichtlich, dass dies eine sehr schlechte Idee war.
Die Implementierung von CachingCoveredFileAnalyser
sieht jetzt so aus:
CachingCoveredFileAnalyser.php
. Die Informationen werden nicht mehr in fünf separaten Cache-Dateien gespeichert und die gleichen Informationen werden nicht mehr mehrfach von der Festplatte gelesen.
Bei der Arbeit hieran habe ich gelernt, dass
file_exists()
bis zu hundertmal langsamer ist als is_dir()
oder is_file()
. Obwohl ich keinen Unterschied in der Performance messen konnte, wenn file_exists()
im Code von php-code-coverage verwendet wurde, ersetzte ich dennoch Aufrufe von file_exists()
durch Aufrufe von is_file()
.
Zu guter Letzt
Die erste Implementierung des Cache für die Ergebnisse der statischen Codeanalyse war zu naiv. Weder das saubere Design, CoveredFileAnalyser
Schnittstelle mit den Implementierungen ParsingCoveredFileAnalyser
und CachingCoveredFileAnalyser
, noch die automatisierten Tests konnten helfen, diese Naivität aufzudecken. Schließlich konnten die automatisierten Tests nur sicherstellen, dass der Cache funktioniert. Das Qualitätsziel der Performance überprüften die Tests natürlich nicht. Nur verstärktes Testen im Sinne von Benchmarks hätte das Problem aufdecken können.
Weiter oben schrieb Martin Völker:
Mein Gedanke war, jetzt schreibe ich ihm einfach mal eine E-Mail. [...] Wird da eine Antwort kommen und wenn ja, wann?
Natürlich kann man mich per E-Mail kontaktieren. Und selbstverständlich bemühe ich mich, jede E-Mail, die mich erreicht, zu beantworten.
Probleme mit PHPUnit (oder anderen Open Source-Projekten) sollten primär im entsprechenden Issue Tracker gemeldet werden. Manchmal ist es jedoch nicht einfach oder sogar unmöglich, ein Problem dort in aller Öffentlichkeit zu melden. Beispielsweise dann, wenn das Problem nur in der eigenen Umgebung beziehungsweise nur mit dem eigenen Code, den man aber nicht öffentlich teilen kann oder will, reproduzierbar ist. In solchen Fällen biete ich immer an, was ich auch Martin Völker angeboten habe, und was er oben im Detail beschrieben hat.
Übrigens: bei Problemen, die nicht direkt etwas mit meinen Open Source-Projekten zu tun haben, kann ich auch helfen.